
Tnnls 2022 Towards Personalized Federated Learning
PFL 为了解决一般的 FL 中的问题:
在异质性强的数据上收敛慢。
模型对于本地缺乏个性化。
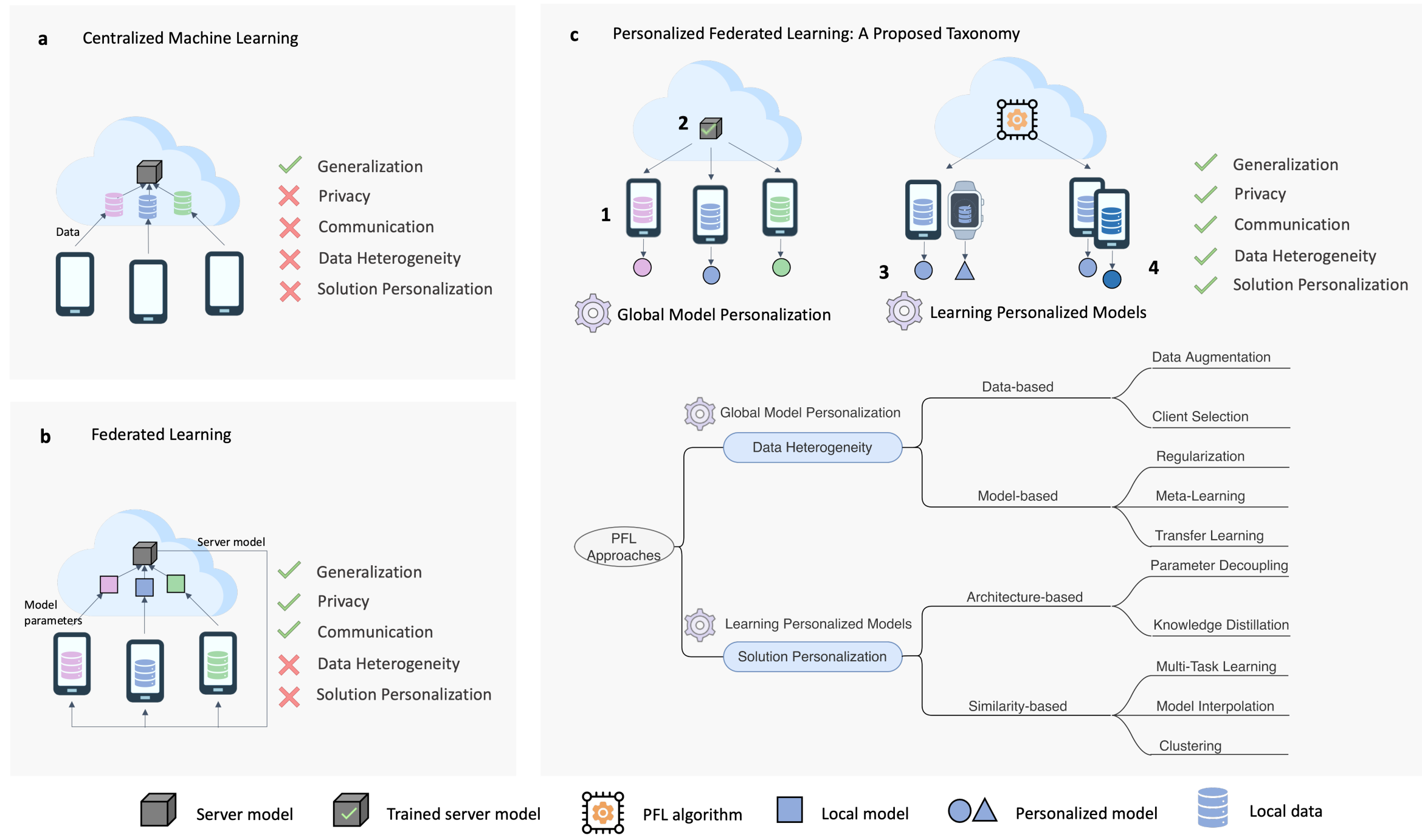
本文将 PFL 分为两类:Global Model Personalization 和 Learning Personalized Models。
Global Model Personalization:先训练一个全局的 FL 模型,然后在本地数据集上进行额外的训练来达到个性化。
Learning Personalized Models:在训练阶段就加入个性化。
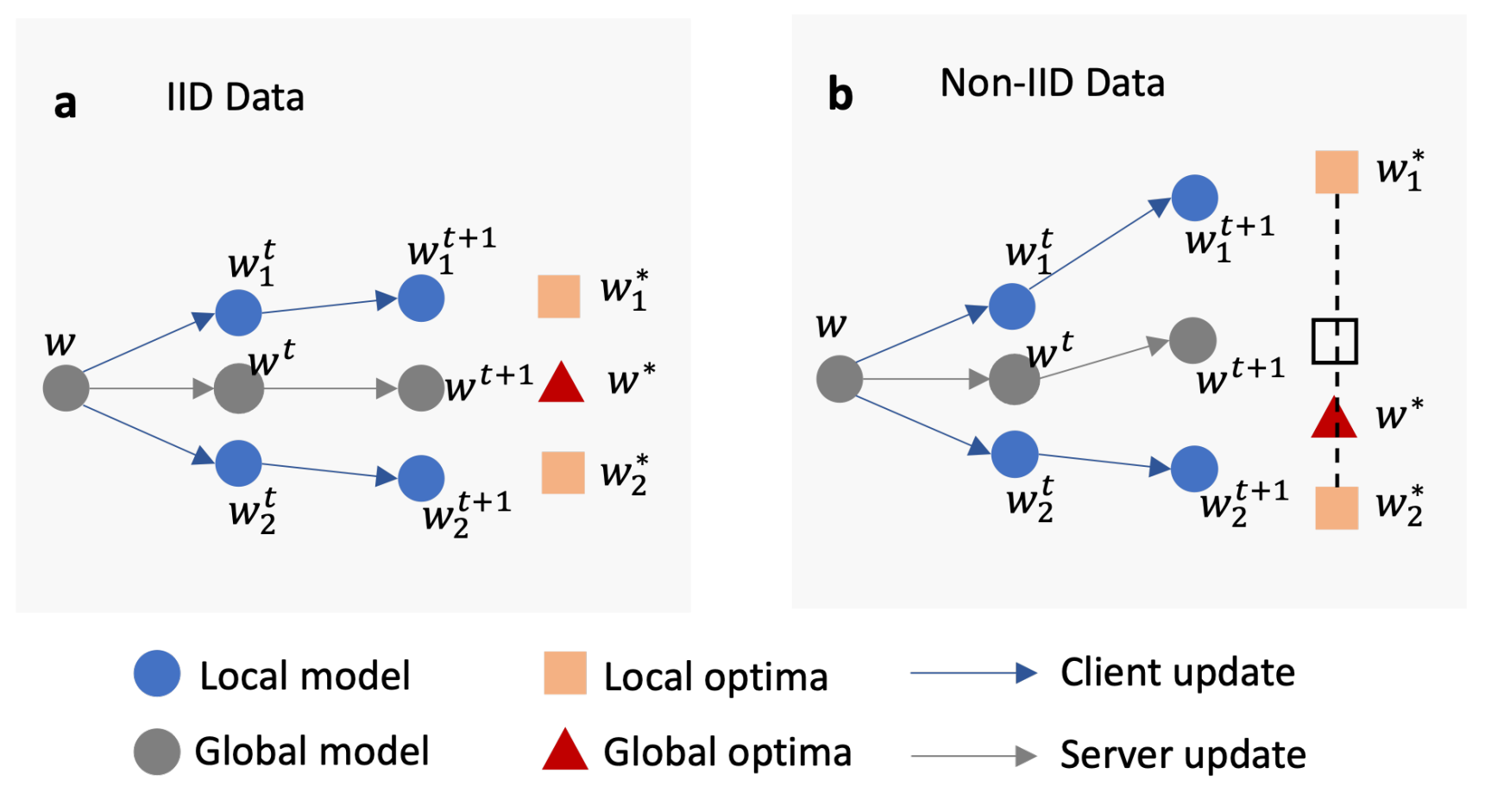
标准的 FL:
本地学习:
为了在泛化和个性化性能之间取得平衡,PFL 介于标准 FL 和本地学习之间。
Global Model Personalization
Data-based Approaches
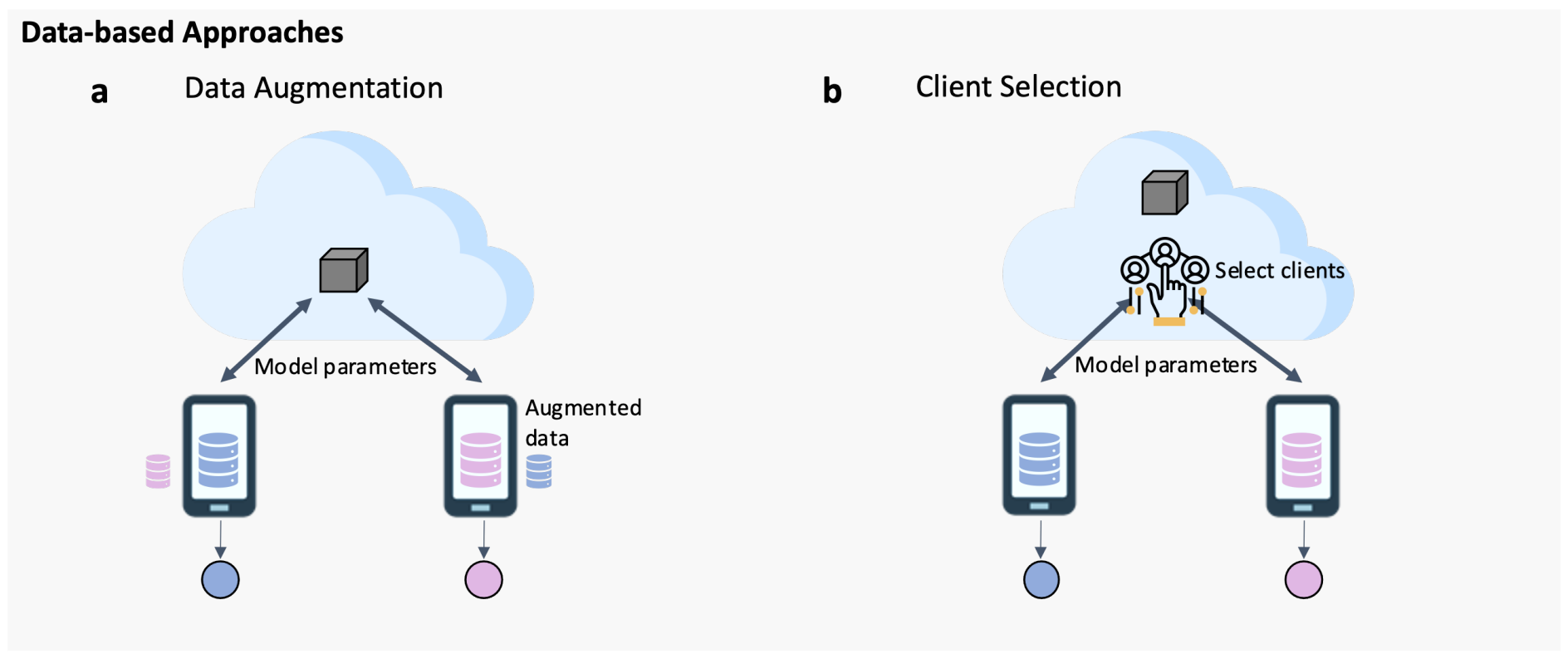
为了减少异质性。
Data Augmentation
数据共享策略:将一小部分全局数据按类别平衡分布到每个客户端。实验显示,添加少量数据有可能获得显著的准确性提升(约30%)。
FAug:一种联邦增强方法,在 FL 服务器中训练一个生成对抗网络(GAN)模型。一些数据样本被上传到服务器来训练 GAN 模型。然后,训练好的 GAN 模型被分发到每个客户端,以生成额外的数据来增强其本地数据,从而产生一个 IID 数据集。
Astraea:一个自平衡的 FL 框架,用于通过使用基于 Z-score 的数据增强和本地数据的下采样来处理类别不平衡。FL 服务器需要关于客户端本地数据分布的统计信息(例如,类别大小,均值和标准差值)。
FedHome:该算法使用 FL 训练一个生成卷积自编码器(GCAE)模型。在FL过程结束后,每个客户端在一个本地增强的类平衡数据集上进行进一步的个性化。这个数据集是通过在基于本地数据的编码网络的低维特征上执行 SMOTE 算法来生成的。
Client Selection
选择更同质的数据分布的客户端,来提升全局模型的泛化能力。
FAVOR:在每个训练轮次中选择一部分参与的客户端,以减轻由 non-IID 数据引入的偏差。设计了一种基于深度 Q-learning 的客户端选择公式,目标是在最小化通信轮次的同时,最大化准确性。
多臂老虎机公式:一种基于多臂老虎机公式的客户端选择算法,以选择类别不平衡最小的客户端子集。通过比较提交给 FL 服务器的本地梯度更新与从服务器上的平衡代理数据集推断出的梯度的相似性,来估计本地类别分布。
TiFL:一个基于层级的FL系统(TiFL),该系统根据训练性能将客户端分组到层中。该算法通过优化准确性和训练时间,自适应地从同一层中选择参与每个训练轮次的客户端。这有助于缓解由数据和资源异质性引起的性能问题。
FedSAE:一个自适应的 FL 系统,它在每个训练轮次中自适应地选择本地训练损失较大的客户端,以加速全局模型的收敛。还提出了一个预测每个客户端可承受工作负载的机制,以便动态调整每个客户端的本地训练周期数,从而提高设备的可靠性。
Model-based Approaches
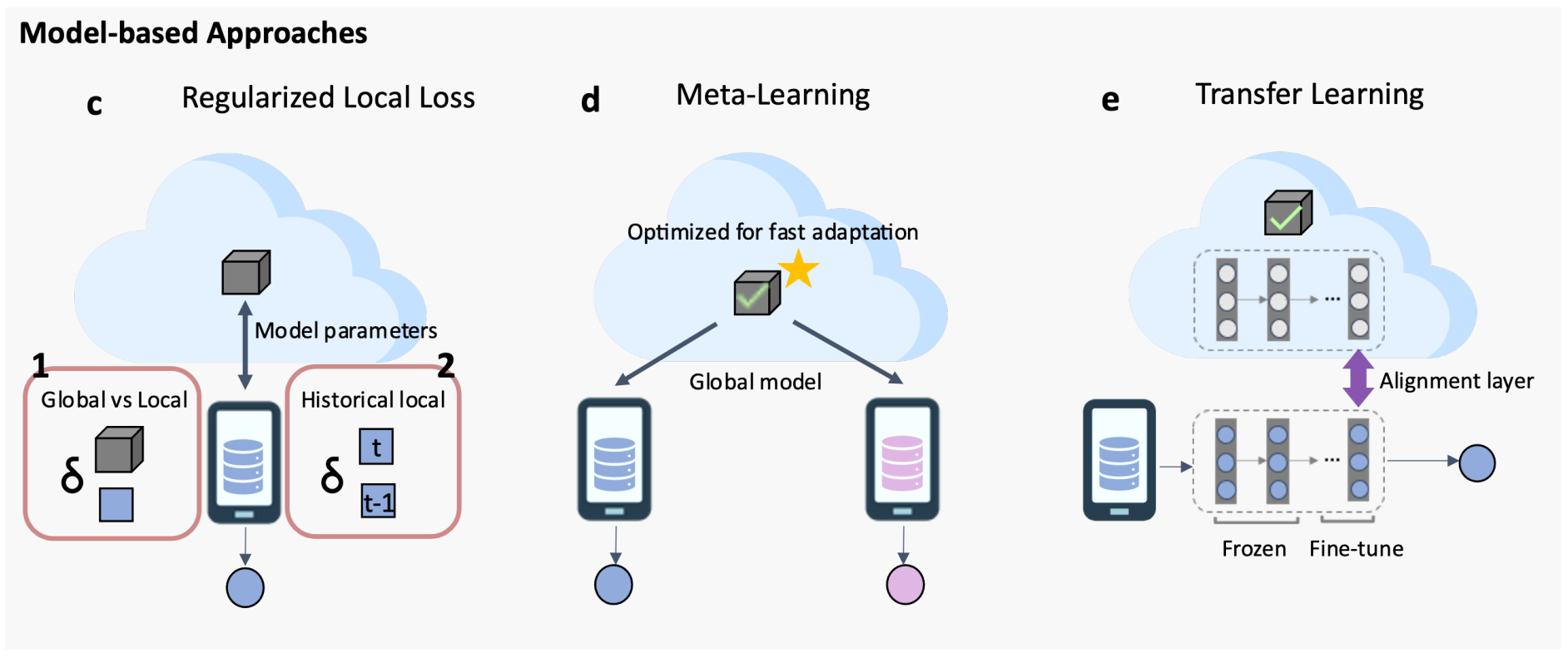
Regularized Local Loss
用正则化来限制本地更新的影响,提高全局模型的收敛稳定性和泛化性。
FedCL:进一步考虑了参数重要性,在使用连续学习领域的弹性权重固化(EWC)的正则化本地损失函数中。
SCAFFOLD:使用方差减少来减轻客户端漂移的影响,该漂移导致本地和全局模型之间的权重发散。
MOON:一种基于对比学习的 FL - MOON。MOON 的目标是减小本地模型和全局模型之间学习到的表示之间的距离(即减轻权重发散),并增加给定本地模型和其先前本地模型之间学习到的表示之间的距离(即加速收敛)。
Meta-learning
元学习算法分两个阶段:元训练和元测试。将 FL 的训练阶段视作为元学习的训练阶段,将 FL 模型个性化阶段视作为元学习的测试阶段,可以很自然的将元学习模型迁移到个性化联邦学习中。
Per-FedAvg:
Transfer Learning
FedMD:一个基于 TL 和知识蒸馏的 FL 框架,供客户使用自己的私有数据设计独立模型。在 FL 训练和知识提炼阶段之前,首先使用在公共数据集上预训练的模型进行 TL。然后,每个客户端都会根据其私有数据对该模型进行微调。
Learning Personalized Models
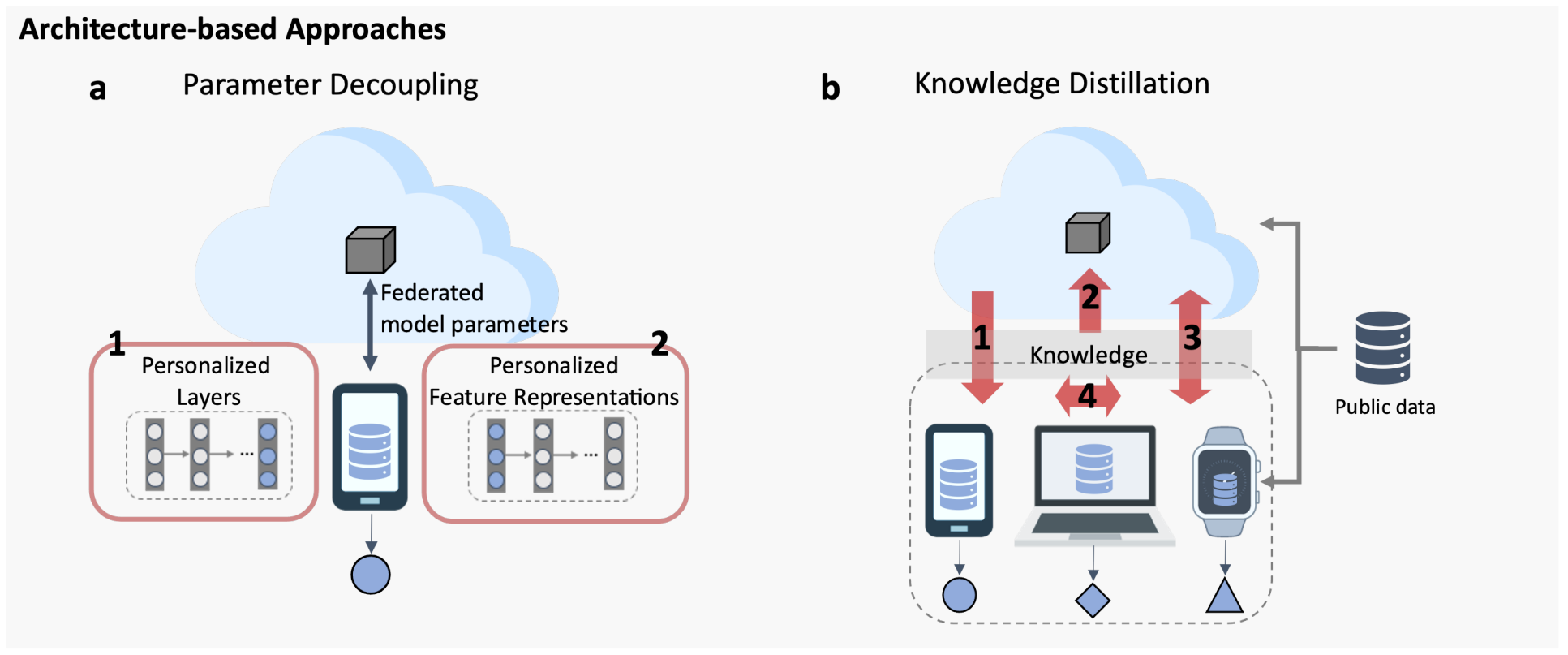
Architecture-based Approaches
Parameter Decoupling
私有参数在客户端上进行本地训练,并且不与联邦学习服务器共享。这使得可以学习到针对特定任务的个性化表示,从而增强个性化定制能力。
基础层+个性化层:为每个客户端设置个性化层,个性化层只在本地训练,而其余的层参数需要上传至云端。
Knowledge Distillation
通过知识蒸馏进行信息传递,客户端之间的模型结构可以不一致。
Similarity-based Approaches
基于相似性的方法旨在通过建模客户关系来实现个性化。为每个客户学习一个个性化模型,并使相关的客户学习相似的模型。
Multi-task Learning (MTL)
MTL 的目标是训练一个能够同时执行多个相关任务的模型。将联邦学习的每个客户端视为 MTL 中的一个任务。
Model Interpolation
一种使用全局和局部模型的混合来学习个性化模型的新方法,用来平衡泛化与个性化。每个
FL 客户端都会学习一个单独的本地模型。惩罚参数
Clustering
将客户端之间聚类,并且对每一个类训练一个模型。