Chaitanya K. Joshi, Thomas Laurent, and Xavier Bresson. "An Efficient
Graph Convolutional Network Technique for the Travelling Salesman
Problem.", Computing Research Repository abs/1906.01227
(2019)
和
得到
Wouter Kool, Herke van Hoof, and Max Welling. "Attention, Learn to
Solve Routing Problems!", arXiv: Machine Learning (2019)
文章由
将
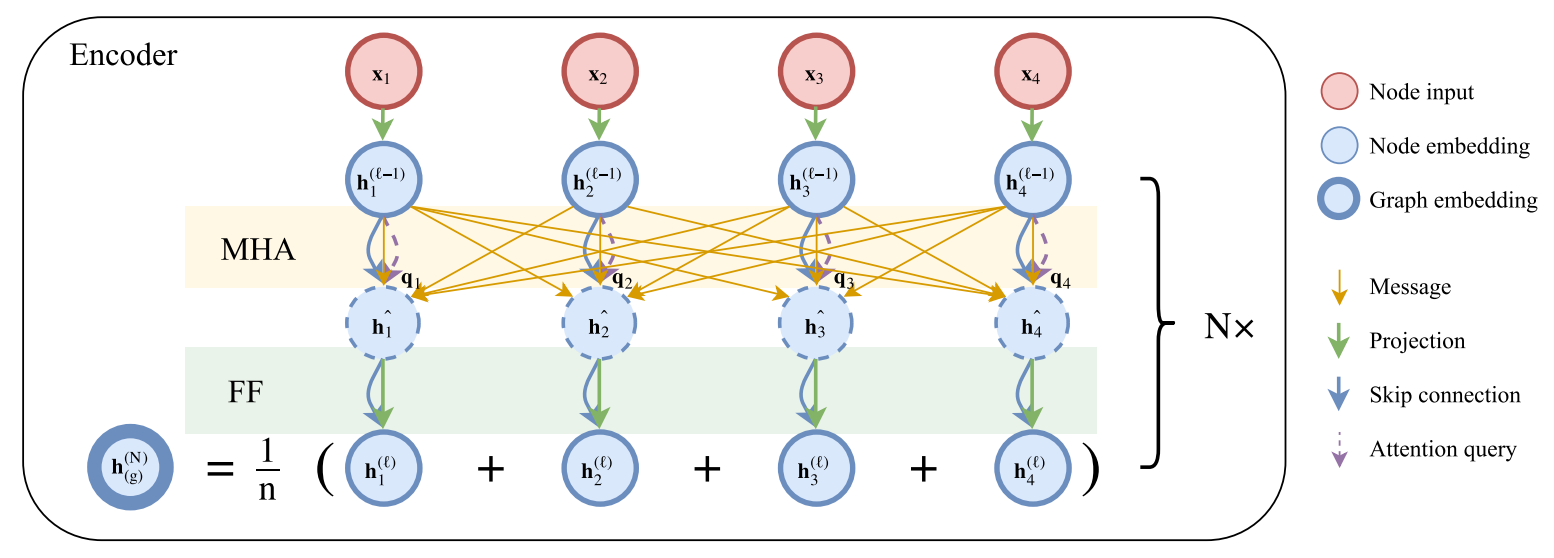
Encoder
没有采用位置编码,输入的节点无次序之分。
先将维度为
Attention mechanism
Multi-head attention
Feed-forward sublayer
Batch normalization
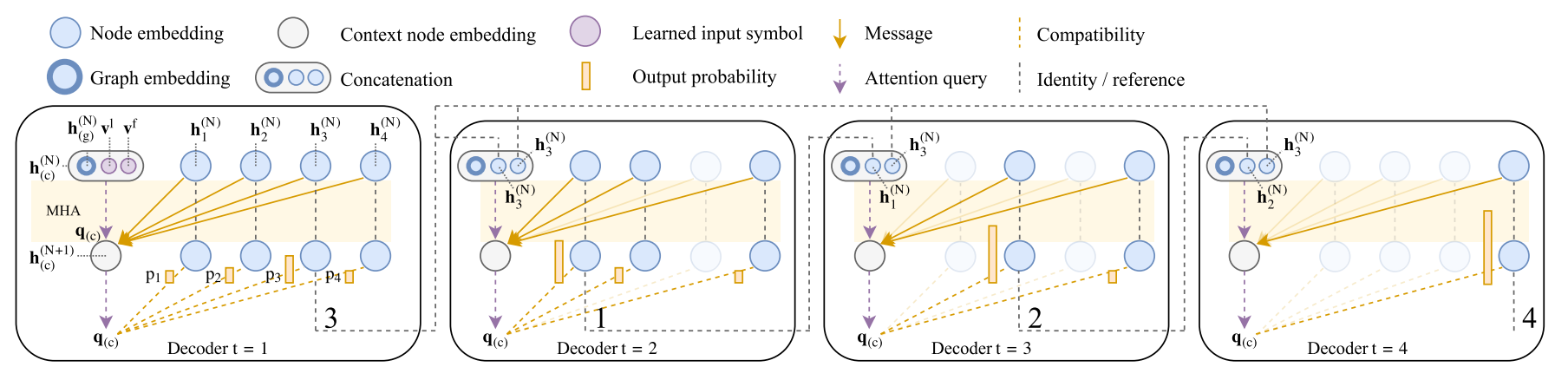
Decoder
将
最后用一个单头注意力层来求出输出概率
Train
policy gradient
论文中的梯度计算公式为:
当